The local dual-cluster comparison became the most important dashboard phase because it gave the project a baseline. Before this, I had an experimental controller and a live dashboard, but that was still too easy to fool myself with.
A controller always looks more convincing when it is judged in isolation. I wanted the same external pressure to hit two Kubernetes clusters at the same time: one side running the experimental orchestration path, the other side exposing familiar HPA and Karpenter behavior. It was not a perfect cloud benchmark, but it was a much better discipline than watching one animated dashboard and calling it evidence.
This phase was about comparison as self-defense. The goal was not to prove that my controller was superior in every sense. The goal was to make the differences concrete enough that I could explain what improved, what merely changed, and what still had not been proven.
How I launched the comparison
I used two Kind clusters: borg-experimental and borg-baseline. The experimental side received the orchestrator loop and bounded Agent A/B/C remediation. The baseline side received HPA and a local warm-node activation controller that approximated Karpenter-like behavior inside Kind. I kept the interpretation boundary visible because local Kind warm-node activation is not AWS Karpenter.
OPEN_BROWSER=0 ./orchestrator_stack/scripts/start_local_dual_cluster_stack.sh
PYTHONPATH=orchestrator_stack .venv/bin/python -m orchestrator.dashboard_server --port 8765 --event-dir orchestrator_stack/runtime/visualization-experimental
PYTHONPATH=orchestrator_stack .venv/bin/python -m orchestrator.comparison_dashboard_server --port 8876 --experimental-kubeconfig ~/Documents/borg_orchestrator_clusters/kubeconfig-experimental --baseline-kubeconfig ~/Documents/borg_orchestrator_clusters/kubeconfig-baseline --experimental-event-dir orchestrator_stack/runtime/visualization-experimentalThe comparison became much more meaningful after I applied the same style of pressure to both clusters. The captured dashboard came from a severe admission-cap style stimulus: 130 replicas, explicit CPU and memory requests, and an intentionally constrained scheduling situation. I wanted the dashboard to show backlog, not just happy-path autoscaling.
EXPERIMENTAL_KUBECONFIG=$HOME/Documents/borg_orchestrator_clusters/kubeconfig-experimental BASELINE_KUBECONFIG=$HOME/Documents/borg_orchestrator_clusters/kubeconfig-baseline PHASE_INDEX=3 EXERCISE_RANDOMIZE=1 EXERCISE_SEED=27 ./orchestrator_stack/scripts/apply_comparison_stimulus.shInterpreting the top dashboard
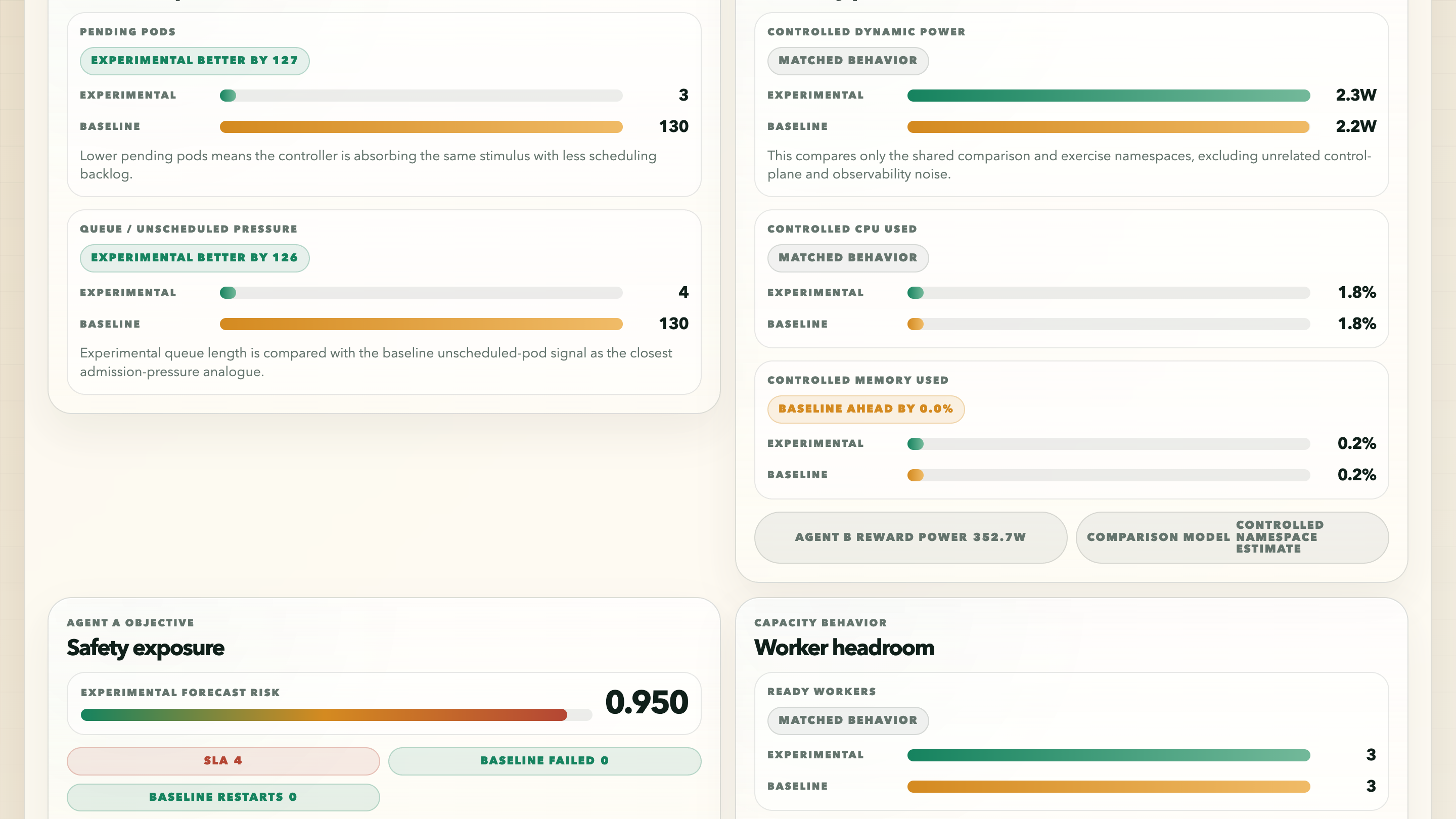
The top comparison view is dense, but that is why I like it. It shows the experimental latest decision, the baseline HPA state, local Karpenter active/warm nodes, and the direct pressure comparison. In the captured run the baseline HPA is maxed at 1/1 replicas with CPU far above the target, while the baseline still has a large Pending backlog. The experimental side is not magically free of pressure, but it is visibly handling the shared stimulus differently.
The most important number in the screenshot is not a single reward score. It is the backlog gap: experimental pending 3 vs baseline pending 130. The dashboard labels this as experimental better by 127, which is much more readable than showing a raw delta and forcing me to remember which direction is good.
Why I added semantic comparison labels
At first the comparison dashboard was basically a metric pile. That was not enough. Lower pending pods is better. Lower restarts is better. Lower dynamic power is usually better under the same controlled stimulus. Higher ready workers can be better when schedulable capacity matters. A raw negative delta does not tell the reader any of that.
So I made the dashboard speak in terms like experimental better, baseline ahead, matched behavior, and objective evidence. It still exposes the numbers, but the UI tells me the direction of the claim. That matters because the dashboard is part of the argument.
specs = [
("Ready workers", ("ready_workers",), "Higher means more schedulable worker capacity is available."),
("Pending pods", ("pending_pods",), "Higher pending count means queue/backlog pressure."),
("Restarts", ("pod_summary", "restarts"), "Container restarts indicate instability or churn."),
(
"Controlled dynamic power W",
("controlled_resource_totals", "estimated_power_watts"),
"Controller-relevant utilization-derived dynamic power, excluding node idle/control-plane noise.",
),
]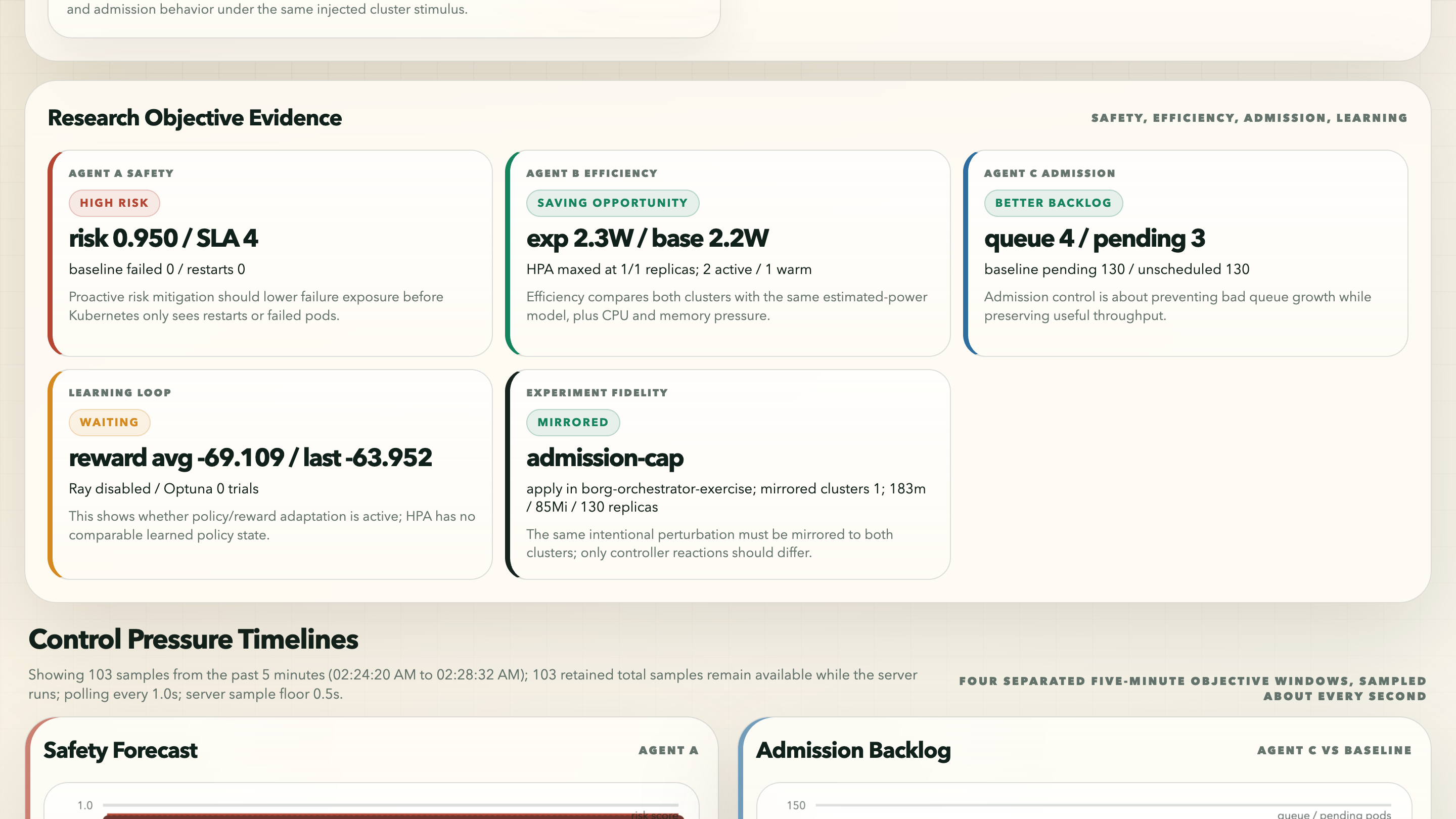
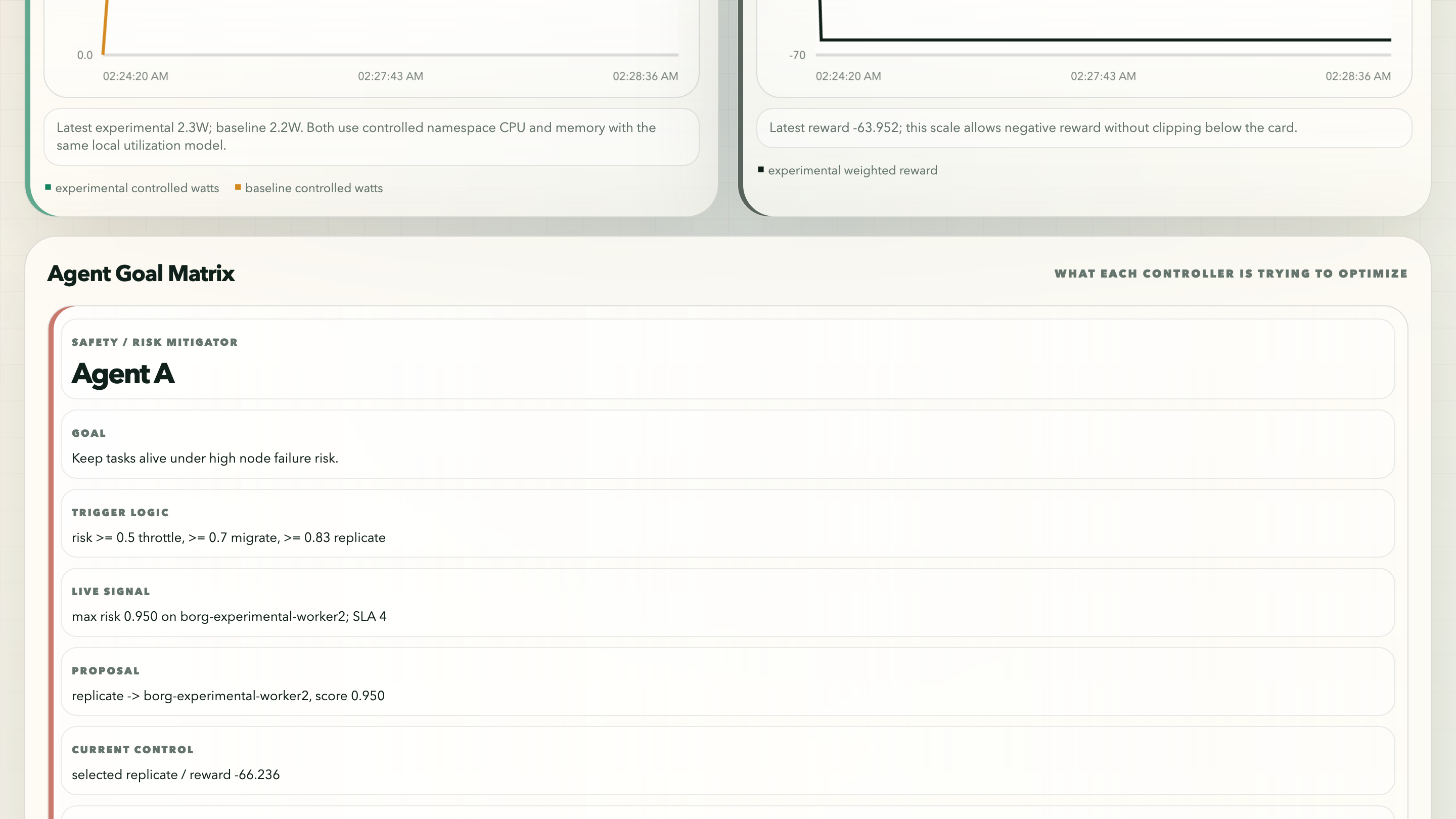
The Agent Goal Matrix was my answer to a problem I kept running into: the experimental controller and the baseline are not optimizing the same internal objective. HPA is reactive scaling logic. Karpenter is capacity provisioning. Agent A/B/C is an explicit multi-objective controller. The dashboard needed to compare observable outcomes while still saying which objective each agent was responsible for.
Controlled resource totals
One repair I made here was narrowing the energy/resource comparison to controlled namespaces. If I included every bit of cluster noise, the dashboard could accidentally compare observability overhead or control-plane background work. That would make the energy story weak. The comparison dashboard therefore tracks controlled CPU, memory, requests, and utilization-derived dynamic watts for the shared comparison and exercise namespaces.
Full comparison dashboard capture. I kept the full page because the top cards, objective evidence, timelines, agent matrix, controller narrative, and interpretation boundary are meant to be read together.
What this comparison did and did not prove
This local comparison did not prove that my controller beats production EKS HPA plus real AWS Karpenter. That would be a much bigger claim and would require real cloud runs. What it did prove for me was narrower and still useful: I could run two local clusters under shared pressure, collect live metrics from both, apply bounded experimental remediation on one side, and show the behavioral difference in a dashboard.
That was the point where the project finally matched the frustration that started it. I was no longer just staring at HPA and Pending pods after the fact. I had a local experiment where pressure, controller decisions, and baseline behavior were visible at the same time.
The comparison setup made the project more honest. It replaced vague confidence with side-by-side behavior, semantic labels, and controlled resource totals. That is the kind of evidence a serious engineering story needs before it starts making larger claims.