local dual-cluster comparison은 이 프로젝트에서 가장 중요한 dashboard 단계가 되었다. baseline을 만들었기 때문이다. 그 전에도 experimental controller와 live dashboard는 있었지만, 그것만으로는 스스로를 속이기 너무 쉬웠다.
controller는 혼자 평가될 때 언제나 더 그럴듯해 보인다. 나는 같은 외부 압력이 두 Kubernetes cluster에 동시에 들어가길 원했다. 한쪽은 experimental orchestration path를 실행하고, 다른 한쪽은 익숙한 HPA와 Karpenter behavior를 보여주는 구조였다. 완벽한 cloud benchmark는 아니었지만, 하나의 animated dashboard를 보고 evidence라고 부르는 것보다는 훨씬 나은 규율이었다.
이 단계는 comparison을 자기방어 장치로 쓰는 과정이었다. 목표는 내 controller가 모든 면에서 우월하다고 증명하는 것이 아니었다. 무엇이 개선됐고, 무엇은 단지 달라졌고, 무엇은 아직 증명되지 않았는지 설명할 수 있을 만큼 차이를 구체화하는 것이었다.
비교를 실행한 방식
나는 borg-experimental과 borg-baseline이라는 두 개의 Kind cluster를 사용했다. experimental 쪽에는 orchestrator loop와 bounded Agent A/B/C remediation을 넣었다. baseline 쪽에는 HPA와, Kind 내부에서 Karpenter-like behavior를 근사하는 local warm-node activation controller를 넣었다. local Kind warm-node activation은 AWS Karpenter가 아니기 때문에, 해석의 경계는 계속 눈에 보이게 남겨두었다.
OPEN_BROWSER=0 ./orchestrator_stack/scripts/start_local_dual_cluster_stack.sh
PYTHONPATH=orchestrator_stack .venv/bin/python -m orchestrator.dashboard_server --port 8765 --event-dir orchestrator_stack/runtime/visualization-experimental
PYTHONPATH=orchestrator_stack .venv/bin/python -m orchestrator.comparison_dashboard_server --port 8876 --experimental-kubeconfig ~/Documents/borg_orchestrator_clusters/kubeconfig-experimental --baseline-kubeconfig ~/Documents/borg_orchestrator_clusters/kubeconfig-baseline --experimental-event-dir orchestrator_stack/runtime/visualization-experimental두 cluster에 같은 스타일의 압박을 걸고 나서야 비교가 훨씬 의미 있어졌다. 캡처한 dashboard는 꽤 강한 admission-cap 스타일 자극에서 나온 것이다. 130 replicas, 명시적인 CPU와 memory requests, 그리고 의도적으로 제약을 준 scheduling 상황. dashboard가 happy-path autoscaling만 보여주는 대신 backlog를 보여주길 원했다.
EXPERIMENTAL_KUBECONFIG=$HOME/Documents/borg_orchestrator_clusters/kubeconfig-experimental BASELINE_KUBECONFIG=$HOME/Documents/borg_orchestrator_clusters/kubeconfig-baseline PHASE_INDEX=3 EXERCISE_RANDOMIZE=1 EXERCISE_SEED=27 ./orchestrator_stack/scripts/apply_comparison_stimulus.sh상단 dashboard 해석하기
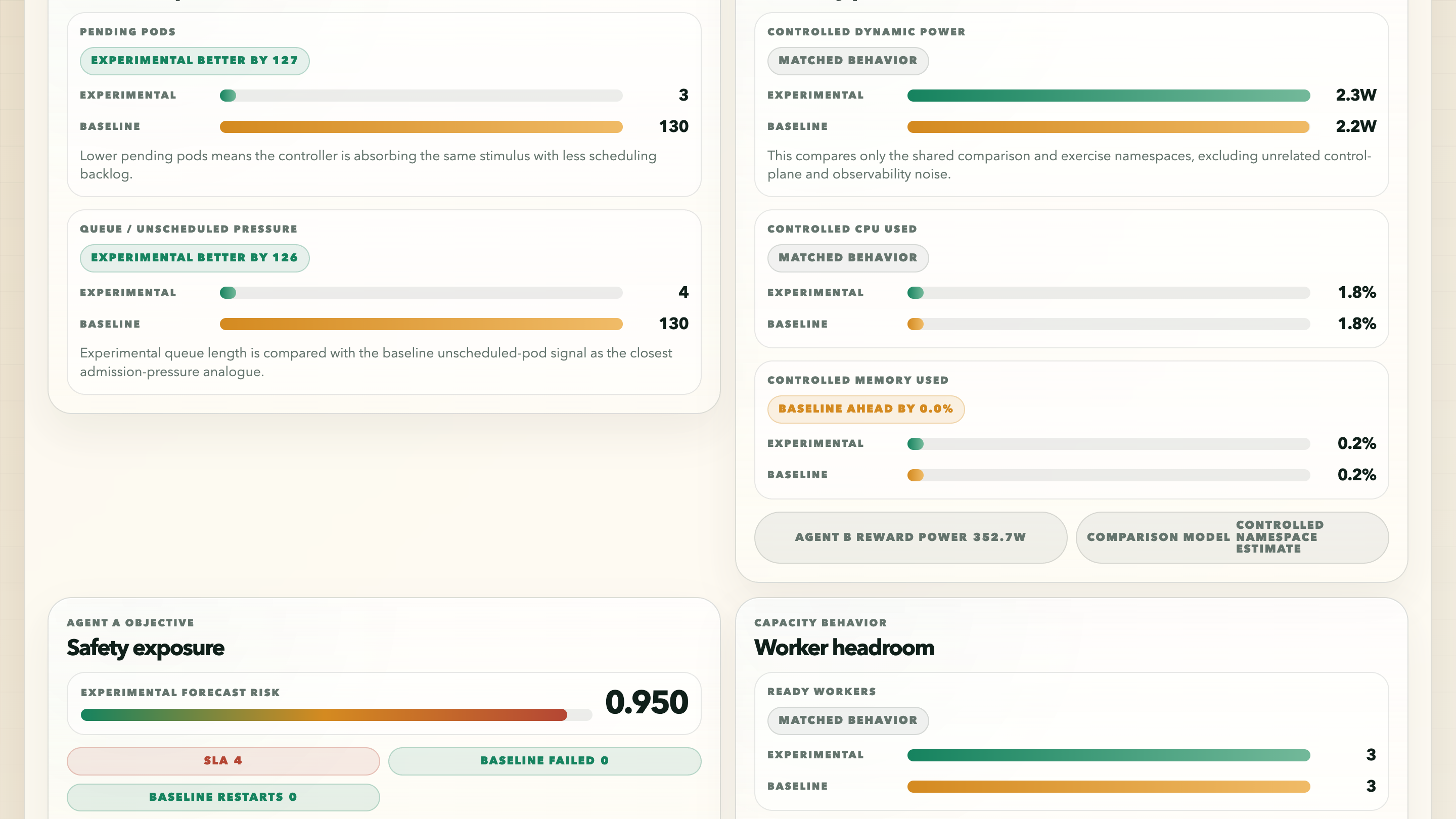
상단 comparison view는 정보가 빽빽하지만, 그래서 마음에 든다. experimental latest decision, baseline HPA state, local Karpenter active/warm nodes, 그리고 직접적인 pressure comparison을 한 화면에 보여준다. 캡처된 run에서 baseline HPA는 target보다 훨씬 높은 CPU를 보이면서도 1/1 replicas로 maxed out 상태이고, baseline에는 여전히 큰 Pending backlog가 남아 있다. experimental 쪽이 압박에서 마법처럼 자유로운 것은 아니지만, 같은 자극을 분명히 다르게 처리하고 있다.
스크린샷에서 가장 중요한 숫자는 단일 reward score가 아니다. backlog gap이다. experimental pending 3 vs baseline pending 130. dashboard는 이를 experimental이 127만큼 better하다고 표시한다. raw delta만 보여주고 어느 방향이 좋은지 내가 기억하게 만드는 것보다 훨씬 읽기 좋다.
semantic comparison label을 추가한 이유
처음 comparison dashboard는 사실상 metric 뭉치에 가까웠다. 그걸로는 부족했다. Pending pods는 낮을수록 좋다. Restarts도 낮을수록 좋다. 같은 controlled stimulus 아래에서는 dynamic power도 보통 낮을수록 좋다. schedulable capacity가 중요할 때는 ready workers가 높은 편이 더 나을 수 있다. raw negative delta만으로는 독자가 이런 맥락을 알 수 없다.
그래서 dashboard가 experimental better, baseline ahead, matched behavior, objective evidence 같은 표현으로 말하게 만들었다. 숫자는 여전히 드러내되, UI가 claim의 방향을 알려준다. dashboard 자체가 논증의 일부이기 때문에 이 점이 중요하다.
specs = [
("Ready workers", ("ready_workers",), "Higher means more schedulable worker capacity is available."),
("Pending pods", ("pending_pods",), "Higher pending count means queue/backlog pressure."),
("Restarts", ("pod_summary", "restarts"), "Container restarts indicate instability or churn."),
(
"Controlled dynamic power W",
("controlled_resource_totals", "estimated_power_watts"),
"Controller-relevant utilization-derived dynamic power, excluding node idle/control-plane noise.",
),
]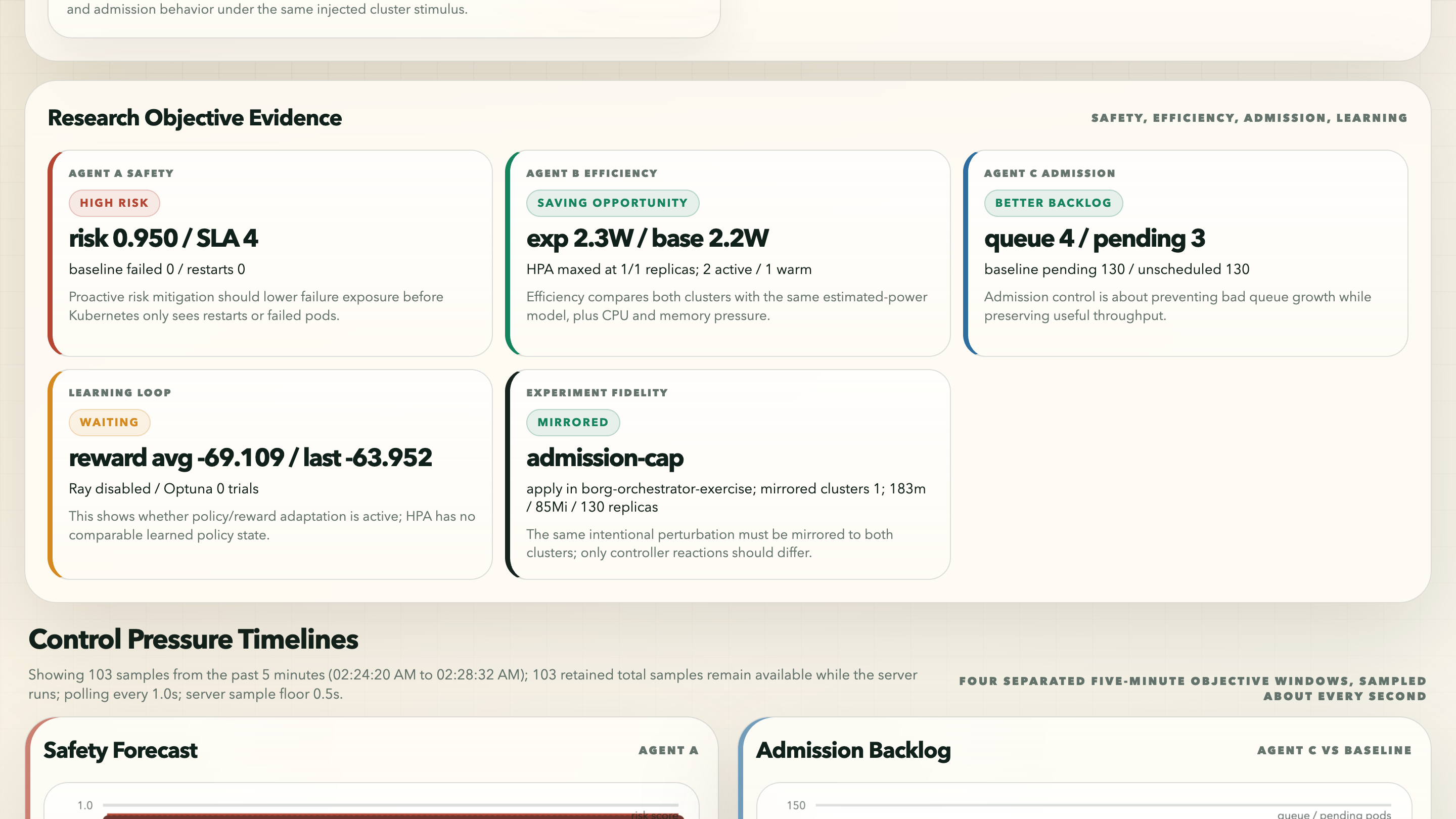
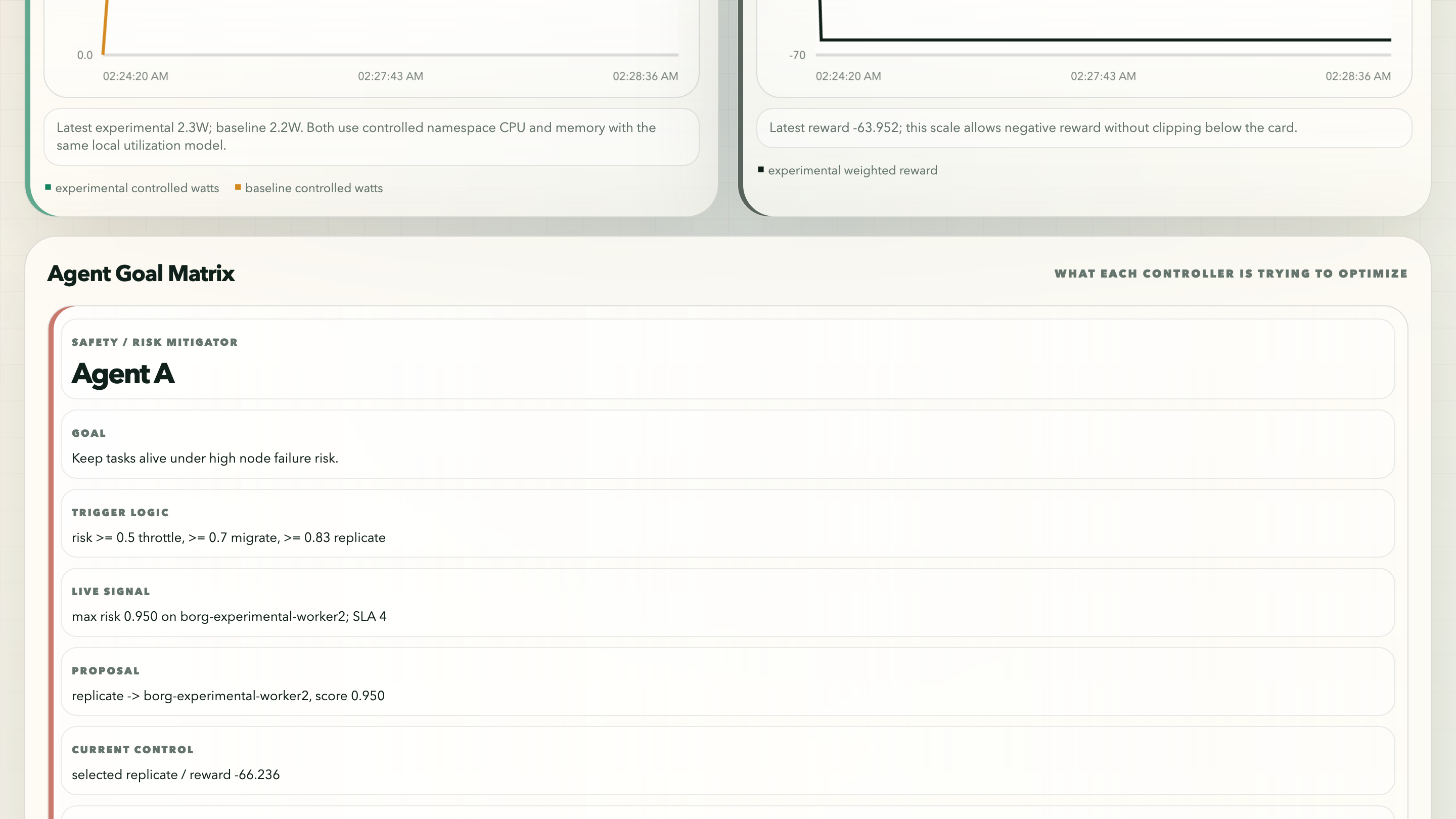
Agent Goal Matrix는 계속 마주치던 문제에 대한 내 답이었다. experimental controller와 baseline은 같은 internal objective를 최적화하지 않는다. HPA는 reactive scaling logic이다. Karpenter는 capacity provisioning이다. Agent A/B/C는 명시적인 multi-objective controller다. dashboard는 observable outcomes를 비교하면서도, 각 agent가 어떤 objective를 맡고 있는지 말할 필요가 있었다.
Controlled resource totals
여기서 고친 것 중 하나는 energy/resource comparison을 controlled namespaces로 좁힌 일이었다. cluster noise를 전부 포함하면 dashboard가 실수로 observability overhead나 control-plane background work를 비교할 수 있다. 그러면 energy story가 약해진다. 그래서 comparison dashboard는 shared comparison과 exercise namespaces에 대해 controlled CPU, memory, requests, 그리고 utilization-derived dynamic watts를 추적한다.
전체 comparison dashboard 캡처. top cards, objective evidence, timelines, agent matrix, controller narrative, interpretation boundary는 함께 읽혀야 한다고 봤기 때문에 full page를 그대로 남겼다.
이 비교가 증명한 것과 증명하지 못한 것
이 로컬 비교가 내 controller가 production EKS HPA와 실제 AWS Karpenter 조합보다 낫다는 것을 증명한 것은 아니다. 그건 훨씬 큰 claim이고, 실제 cloud run이 필요하다. 이 비교가 나에게 증명해준 것은 더 좁지만 여전히 유용한 사실이었다. 같은 pressure 아래에서 두 개의 local cluster를 돌리고, 양쪽에서 live metrics를 수집하고, 한쪽에는 bounded experimental remediation을 적용하고, 그 behavioral difference를 dashboard에 보여줄 수 있다는 것.
그 지점에서 프로젝트는 처음의 답답함과 드디어 맞닿았다. 나는 더 이상 사후에 HPA와 Pending pods만 바라보고 있지 않았다. pressure, controller decisions, baseline behavior를 동시에 볼 수 있는 local experiment를 갖게 됐다.
comparison setup은 프로젝트를 더 정직하게 만들었다. 막연한 자신감을 side-by-side behavior, semantic label, controlled resource total로 바꿨다. 더 큰 주장을 하기 전에 serious engineering story가 가져야 할 증거에 가까웠다.