문제의 시작
개념을 이해한 뒤에는 실제로 message가 broker를 거쳐 consumer까지 도착하는 장면을 확인해야 한다. Kafka는 설정과 코드가 분리되어 있어 작은 예제를 직접 만들어보는 편이 가장 빠르다. 이 글은 Spring Boot에서 producer와 consumer를 연결하며 최소한의 메시지 흐름을 검증한 기록이다.
우선 kafka 설치이다.
구현하면서 확인한 흐름
brew install kafka
이후
zkServer start //zooKeeper 시작
kafka-server-start /opt/homebrew/etc/kafka/server.properties //kafka 시작 - brew 로 설치하지 않았다면 /usr/local/~ 에 있음다음으로 간단하게 topic 을 생성해보자.
kafka-topics --create --topic test --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1test 라는 이름의 topic 을 kafka server (localhost:9092) 에 생성한다.
replication factor 는 가지고 있을 복사본의 개수를 의미한다. 여기서는 partition 당 복사본의 개수가 1이며, production 환경으로 가게 되면 fault tolerance 를 위해 3 이상의 replication factor 가 권장된다.
partitions 는 간단히 partition 의 개수를 의미한다. 이 개수가 늘어나면 topic log 가 parallel 하게 data 가 분산되어 fault tolerance 와 scalability 가 증가한다.
다음으로 CLI 에서 producer 와 consumer 를 간단히 테스트해본다.
결과를 어떻게 검증했는가
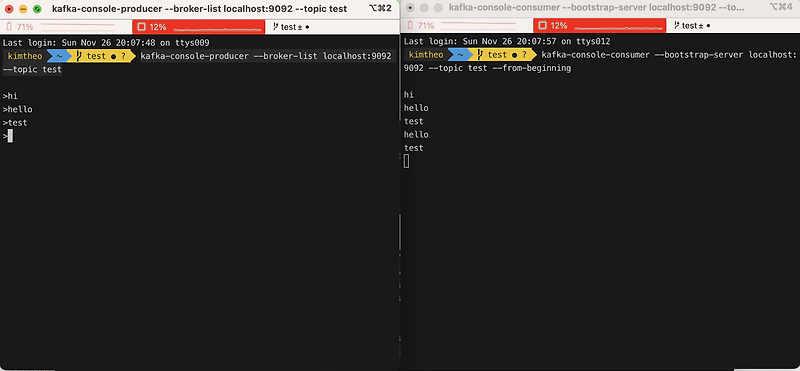
kafka-console-producer --broker-list localhost:9092 --topic test
kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning다음으로 Spring Boot Application 에 integration 을 시도해본다.
implementation 'org.springframework.kafka:spring-kafka'우선 build.gradle 에 dependency 를 추가한다.
다음으로 topic 을 생성하는 admin config 인데, 이를 kafka CLI 에서도 할 수 있지만 스프링부트 안에서도 가능하다.
@Configuration
public class KafkaTopicConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapAddress;
@Bean
public KafkaAdmin kafkaAdmin() {
Map<String, Object> configs = new HashMap<>();
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
return new KafkaAdmin(configs);
}
@Bean
public NewTopic topic1() {
return new NewTopic("baeldung", 1, (short) 1);
}
}매번 @Value annotation 사용할 때마다 실수하는데 intelliJ 사용 시 annotation processing 을 켜줘야 한다.
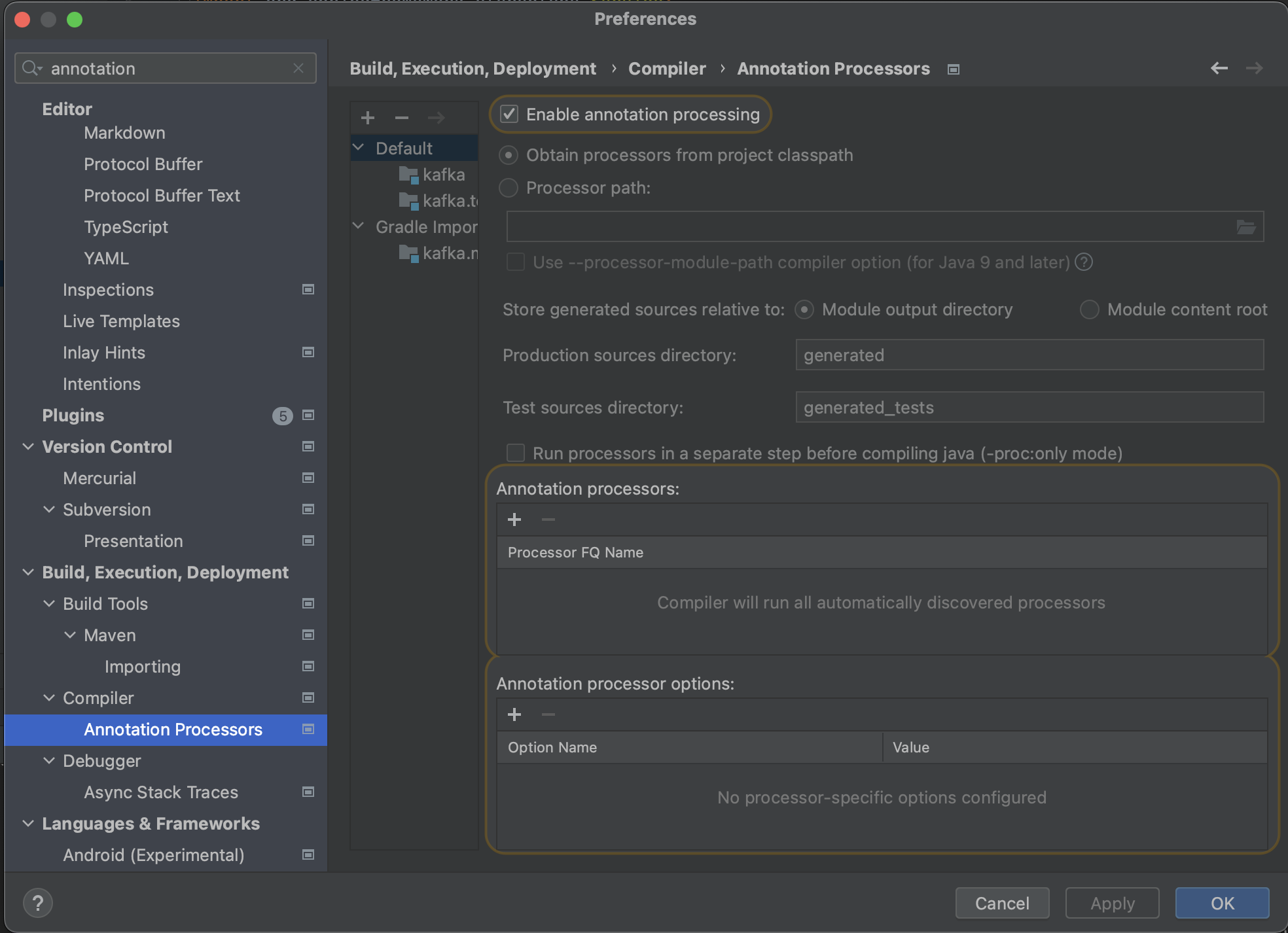
KafkaAdmin bean을 생성한다. configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress)는 configuration map에 bootstrap address를 설정한다.
아래 NewTopic 함수는 이전 CLI 에서 topic 을 생성했듯 프로그래밍을 통해 topic 을 생성하는데,
kafka-topics --create --topic baeldung --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1에 상응하는 topic 생성 함수가 되겠다.
다음으로는 producer 와 consumer service layer 다.
@Component
public class KafkaConsumerService {
@KafkaListener(topics = "test", groupId = "my-group")
public void listen(String message) {
System.out.println("Received message in group 'my-group': " + message);
}
}
@Service
public class KafkaProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message);
}
}실습 기준
간단한 예제라도 producer, topic, consumer group, serialization 흐름을 직접 통과해보면 Kafka가 덜 추상적으로 느껴진다. 이후 real service에 붙일 때는 retry, ordering, idempotency, schema 관리가 따라오지만, 첫 번째 기준점은 message가 어디에서 어디로 이동하는지 눈으로 확인하는 것이다.
지원되는 함수들 쓰는거라 딱히 어려울건 없어보인다.